执行摘要 在这篇博文中,我们展示了如何修改使用 Dask 进行的骨架网络分析,使其在受限 RAM(例如:您的笔记本电脑)下工作。这使其更易于使用:它可以在小型笔记本电脑上运行,而无需访问超级计算集群。示例代码也在此提供 。
目录 骨架结构无处不在
科学问题
计算问题
我们的方法
结果
局限性
遇到的问题
解决方案
下一步是什么?
您可以如何提供帮助
骨架结构无处不在 许多生物结构具有骨架或网络状的形状。我们在各种地方都能看到这些,包括
血管分支 气道分支 大脑中的神经元网络 植物的根系结构 叶片中的毛细血管 ……等等 分析这些骨架的结构可以为我们提供关于该系统生物学的重要信息。
科学问题 在这篇博文中,我们将研究肺内的血管。这些数据由 Marcus Kitchen 、Andrew Stainsby 及其合作团队分享给我们。
该研究小组专注于肺部发育。我们希望将健康肺部的血管与疝气模型肺部的血管进行比较。在疝气模型中,肺部发育不全、受压且更小。
计算问题 这些图像体积形状大约是 1000x1000x1000 像素。这看起来不是很大,但考虑到处理分析涉及的高 RAM 消耗,在笔记本电脑上运行时会崩溃。
如果您内存不足,有两种可能的方法
增加 RAM。在更大的计算机上运行,或转移到超级计算集群。这样做的好处是您无需重写代码,但这确实需要访问更强大的计算机硬件。 管理现有的 RAM。Dask 擅长于此。如果我们使用 Dask,并对我们的数组进行合理的块划分,我们可以管理内存,从而不会触及 RAM 上限并导致崩溃。这样做的好处是您无需购买更多计算机硬件,但这需要重写一些代码。 我们的方法 我们采取了第二种方法,使用 Dask,以便我们可以在 RAM 受限的小型笔记本电脑上运行分析而不会崩溃。这使得它对更多人来说更容易访问。
所有图像预处理步骤将使用 dask-image 和 scikit-image 的 skeletonize
我们使用 skan 作为我们分析流程的核心。skan 是一个用于骨架图像分析的库。给定骨架图像,它可以描述分支的统计数据。为了提高速度,该库使用 numba 进行了加速(如果您好奇,可以在 这场演讲 及其 相关 notebook 中了解更多)。
包含骨架分析完整细节的示例 notebook 可在此处获取 。您可以继续阅读以了解主要亮点。
结果 健康肺部和疝气肺部血管分支的统计数据显示两者之间存在明显差异。
最显著的是血管分支数量的差异。疝气肺部的血管分支数量不到健康肺部的 40%。
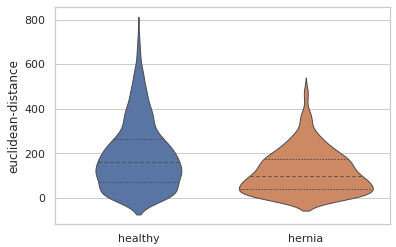
血管的大小也存在定量差异。这里有一个小提琴图,显示了血管分支厚度的分布。我们可以看到,健康肺部有更多的粗血管分支。这与我们预期的结果一致,因为健康肺部比疝气模型的肺部发育得更好。
局限性 我们依赖一个重要的假设:骨架化后,减少的非零像素数据将适合内存。虽然这对于这种大小的数据集(裁剪的兔子肺数据集大约是 1000 x 1000 x 1000 像素)来说是成立的,但对于大得多的数据可能不成立。
在我们的原型工作流程中,Dask 计算也在几个点上触发。理想情况下,所有计算都应推迟到最后阶段。
遇到的问题 这个项目最初打算快速简便地完成。然而事与愿违!
我想做的是将图像数据放入 Dask 数组中,然后使用 map_overlap
Dask 的 map_overlap 函数不能很好地处理来自不同图像块的参差不齐或形状不均匀的结果,而且…… skan 库中的内部函数编写方式与分布式计算不兼容。 解决方案 问题 1:scikit-image 的 skeletonize 函数因内存不足而崩溃 scikit-image 的 skeletonize
我们通过以下方式解决了这个问题
问题 2:Dask 数组块产生的输出参差不齐或不均匀 骨架分析函数将为每个图像块返回长度参差不齐或不均匀的结果。这并不奇怪,因为不同的块在我们的骨架形状中会有不同数量的非零像素。
使用 Dask 数组时,有两个非常常用的函数:map_blocks map_overlap map_blocks 和 map_overlap 处理具有参差不齐输出的函数时,会发生以下情况。
import dask.array as da
import numpy as np
x = da.ones((100, 10), chunks=(10, 10))
def foo(a): # our dummy analysis function
random_length = np.random.randint(1, 7)
return np.arange(random_length)
使用 map_blocks ,一切运行良好
result = da.map_blocks(foo, x, drop_axis=1)
result.compute() # this works well
但是如果我们需要一些重叠才能使函数 foo 正确工作,那么我们就会遇到问题
result = da.map_overlap(foo, x, depth=1, drop_axis=1)
result.compute() # incorrect results
在这里,foo 的结果中的第一个和最后一个元素在结果被连接之前被裁剪掉了,这不是我们想要的!设置关键字参数 trim=False 有助于避免这个问题,除非那样我们会得到一个错误
result = da . map_overlap ( foo , x , depth = 1 , trim = False , drop_axis = 1 )
result . compute () # ValueError
对我们来说不幸的是,在我们的数组块中拥有 1 个像素的重叠非常重要,这样我们才能判断骨架分支是结束了还是继续进入下一个块。
map_overlap 结果的连接方式有些复杂,与其深入研究,更直接的解决方案是改用 Dask delayed 。Chris Roat 提供了一个很好的示例,展示了如何在列表推导式中使用 Dask delayed ,然后使用 Dask 进行连接(原始讨论链接 )。
import numpy as np
import pandas as pd
import dask
import dask.array as da
import dask.dataframe as dd
x = da . ones (( 20 , 10 ), chunks = ( 10 , 10 ))
@ dask . delayed
def foo ( a ):
size = np . random . randint ( 1 , 10 ) # Make each dataframe a different size
return pd . DataFrame ({ 'x' : np . arange ( size ),
'y' : np . arange ( 10 , 10 + size )})
meta = dd . utils . make_meta ([( 'x' , np . int64 ), ( 'y' , np . int64 )])
blocks = x . to_delayed (). ravel () # no overlap
results = [ dd . from_delayed ( foo ( b ), meta = meta ) for b in blocks ]
ddf = dd . concat ( results )
ddf . compute ()
警告: 将 meta 关键字参数传递给函数 from_delayed 非常重要。否则,效率会非常低!
如果没有提供 meta 关键字参数,Dask 会尝试计算它应该是什么。通常这可能是件好事,但在列表推导式中,这意味着这些任务在主要计算开始之前会缓慢地按顺序计算,效率极低。由于我们事先知道分析函数会返回什么样的结果(只是不知道每组结果的长度),我们可以使用 utils.make_meta
问题 3:获取具有重叠的图像块 现在我们使用 Dask delayed 来组合骨架分析结果,我们需要自己处理数组块的重叠。
我们将通过修改 Dask 的 dask.array.core.slices_from_chunks
这是它的样子(gist )
from itertools import product
from dask.array.slicing import cached_cumsum
def slices_from_chunks_overlap ( chunks , array_shape , depth = 1 ):
cumdims = [ cached_cumsum ( bds , initial_zero = True ) for bds in chunks ]
slices = []
for starts , shapes in zip ( cumdims , chunks ):
inner_slices = []
for s , dim , maxshape in zip ( starts , shapes , array_shape ):
slice_start = s
slice_stop = s + dim
if slice_start > 0 :
slice_start -= depth
if slice_stop >= maxshape :
slice_stop += depth
inner_slices . append ( slice ( slice_start , slice_stop ))
slices . append ( inner_slices )
return list ( product ( * slices ))
既然我们可以对一个图像块加上一个额外的重叠像素进行切片,我们只需要一种方法来对数组中的所有块执行此操作。受到这个块迭代 的启发,我们创建了一个类似的迭代器。
block_iter = zip (
np . ndindex ( * image . numblocks ),
map ( functools . partial ( operator . getitem , image ),
slices_from_chunks_overlap ( image . chunks , image . shape , depth = 1 ))
)
meta = dd . utils . make_meta ([( 'row' , np . int64 ), ( 'col' , np . int64 ), ( 'data' , np . float64 )])
intermediate_results = [ dd . from_delayed ( skeleton_graph_func ( block ), meta = meta ) for _ , block in block_iter ]
results = dd . concat ( intermediate_results )
results = results . drop_duplicates () # we need to drop duplicates because it counts pixels in the overlapping region twice
利用这些结果,我们能够创建稀疏骨架图。
问题 4:使用 skan 进行汇总统计 骨架分支统计可以使用 skan summarize 函数计算。这里的问题是该函数需要一个 Skeleton Skeleton 对象会调用不兼容分布式分析的方法。
我们将通过以下方式解决这个问题:首先使用一个小型的虚拟数据集初始化一个 Skeleton
首先我们使用虚拟数据创建一个 Skeleton 对象实例
from skan._testdata import skeleton0
skeleton_object = Skeleton ( skeleton0 ) # initialize with dummy data
然后我们用之前计算的结果覆盖属性
skeleton_object.skeleton_image = ...
skeleton_object.graph = ...
skeleton_object.coordinates
skeleton_object.degrees = ...
skeleton_object.distances = ...
...
最后我们就可以计算骨架分支的汇总统计数据了
from skan import summarize
statistics = summarize ( skel_obj )
statistics . head ()
骨架ID
源节点ID
目标节点ID
分支距离
分支类型
平均像素值
像素值标准差
图像源坐标-0
图像源坐标-1
图像源坐标-2
图像目标坐标-0
图像目标坐标-1
图像目标坐标-2
源坐标-0
源坐标-1
源坐标-2
目标坐标-0
目标坐标-1
目标坐标-2
欧几里得距离
0
1
1
2
1
2
0.474584
0.00262514
22
400
595
22
400
596
22
400
595
22
400
596
1
1
2
3
9
8.19615
2
0.464662
0.00299629
37
400
622
43
392
590
37
400
622
43
392
590
33.5261
2
3
10
11
1
2
0.483393
0.00771038
49
391
589
50
391
589
49
391
589
50
391
589
1
3
5
13
19
6.82843
2
0.464325
0.0139064
52
389
588
55
385
588
52
389
588
55
385
588
5
4
7
21
23
2
2
0.45862
0.0104024
57
382
587
58
380
586
57
382
587
58
380
586
2.44949
骨架ID
源节点ID
目标节点ID
分支距离
分支类型
平均像素值
像素值标准差
图像源坐标-0
图像源坐标-1
图像源坐标-2
图像目标坐标-0
图像目标坐标-1
图像目标坐标-2
源坐标-0
源坐标-1
源坐标-2
目标坐标-0
目标坐标-1
目标坐标-2
欧几里得距离
计数
1095
1095
1095
1095
1095
1095
1095
1095
1095
1095
1095
1095
1095
1095
1095
1095
1095
1095
1095
1095
平均值
2089.38
11520.1
11608.6
22.9079
2.00091
0.663422
0.0418607
591.939
430.303
377.409
594.325
436.596
373.419
591.939
430.303
377.409
594.325
436.596
373.419
190.13
标准差
636.377
6057.61
6061.18
24.2646
0.0302199
0.242828
0.0559064
174.04
194.499
97.0219
173.353
188.708
96.8276
174.04
194.499
97.0219
173.353
188.708
96.8276
151.171
最小值
1
1
2
1
2
0.414659
6.79493e-06
22
39
116
22
39
114
22
39
116
22
39
114
0
25%
1586
6215.5
6429.5
1.73205
2
0.482
0.00710439
468.5
278.5
313
475
299.5
307
468.5
278.5
313
475
299.5
307
72.6946
50%
2431
11977
12010
16.6814
2
0.552626
0.0189069
626
405
388
627
410
381
626
405
388
627
410
381
161.059
75%
2542.5
16526.5
16583
35.0433
2
0.768359
0.0528814
732
579
434
734
590
432
732
579
434
734
590
432
265.948
最大值
8034
26820
26822
197.147
3
1.29687
0.357193
976
833
622
976
841
606
976
833
622
976
841
606
737.835
成功!
我们使用 Dask 实现了分布式骨架分析。你可以在这里 看到包含骨架分析完整细节的示例 notebook。
下一步是什么? 一个好的下一步是修改 skan 库的代码,使其直接支持分布式骨架分析。
您可以如何提供帮助 如果您想参与,有几种选择
尝试在您自己的数据上进行类似的分析。包含完整示例代码的 notebook 可在此处获取 。您可以在 Dask slack 或 twitter 上 分享或提问。 帮助为 skan 添加分布式骨架分析的支持。前往 skan issues 页面 ,如果您想加入,请留言。