本博客文章在最近的 PASC2019 会议上以演讲形式发布。该演讲的幻灯片在此。
我们正在改进Python中可扩展GPU计算的现状。
本文阐述了当前状态,并描述了未来的工作。它还总结并链接了最近几个月发布的其他几篇深入探讨不同主题的博客文章,供感兴趣的读者参考。
我们将大致简要介绍以下类别
对于Python程序员来说,访问GPU性能最简单的方法可能是使用GPU加速的Python库。这些库提供了一套经过良好调优且能很好地集成的常用操作。
许多用户知道像PyTorch和TensorFlow这样的深度学习库,但也有其他几个用于更通用的计算。这些库通常复制流行Python项目的API
这些库构建了流行Python库(如NumPy、Pandas和Scikit-Learn)的GPU加速变体。为了更好地理解相对性能差异,Peter Entschev最近整理了一套基准测试套件,以帮助进行比较。他生成了以下图像,显示了GPU和CPU之间的相对加速比
那里有很多有趣的结果。Peter在他的博客文章中对此进行了更深入的探讨。
然而,更广泛地说,我们看到性能存在变异性。我们对CPU上什么快、什么慢的心理模型不一定适用于GPU。但幸运的是,由于一致的API,熟悉Python的用户可以轻松尝试GPU加速,而无需学习CUDA。
另请参阅这篇关于Numba stencil的近期博客文章以及附加的GPU Notebook
CuPy和RAPIDS等GPU库中的内置操作涵盖了大多数常用操作。然而,在实际场景中,我们经常会遇到需要编写少量自定义代码的复杂情况。在这种情况下,切换到C/C++/CUDA可能具有挑战性,特别是对于主要使用Python的开发者。这就是Numba发挥作用的地方。
Python在CPU上也存在同样的问题。用户通常懒得学习C/C++来编写快速的自定义代码。为了解决这个问题,有一些工具,如Cython或Numba,它们允许Python程序员编写快速的数值计算代码,而无需学习Python语言以外的太多内容。
例如,Numba可以将下面的for循环风格代码在CPU上加速约500倍,从慢速的Python速度提升到快速的C/Fortran速度。
import numba # 我们添加了这两行代码,获得了500倍的加速
@numba.jit # 我们添加了这两行代码,获得了500倍的加速
def sum(x)
total = 0
for i in range(x.shape[0])
total += x[i]
return total
无需切换上下文即可从Python中编写底层高性能代码的能力非常有用,特别是如果您还不了解C/C++或者没有为您设置好编译器工具链(这对于当今大多数Python用户来说都是如此)。
这个好处在GPU上更为突出。虽然许多Python程序员懂一点C,但很少有人了解CUDA。即使他们懂,也可能难以设置编译器工具和开发环境。
介绍 numba.cuda.jit,Numba用于CUDA的后端。Numba.cuda.jit允许Python用户在不离开Python会话的情况下,以交互方式编写、编译和运行用Python编写的CUDA代码。这是一张在Jupyter Notebook中编写对2D图像进行平滑处理的Stencil计算的截图
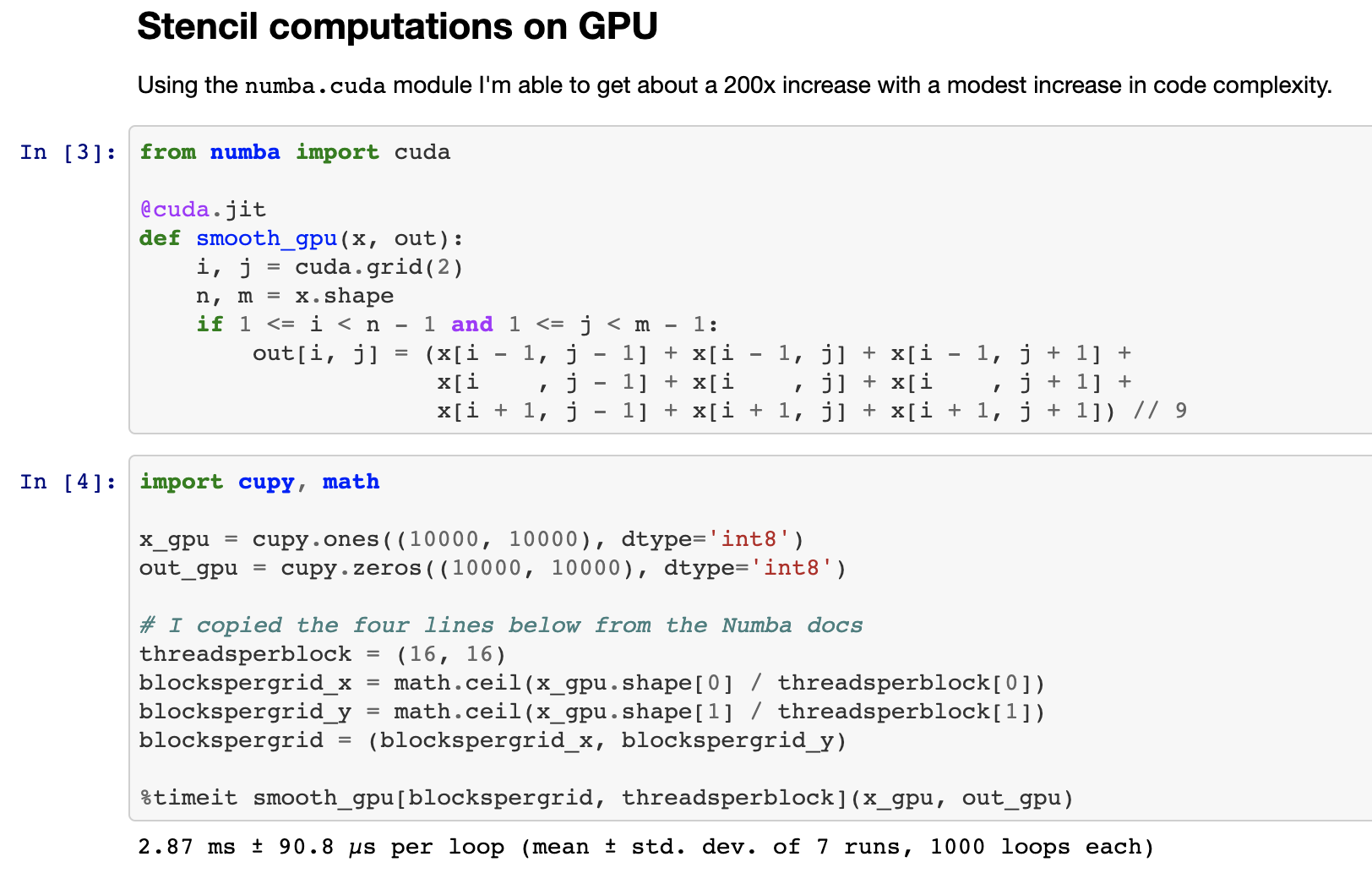
这是一个简化的Numba CPU/GPU代码比较,以比较编程风格。GPU代码相对于单个CPU核心获得了200倍的加速。
@numba.jit
def _smooth(x)
out = np.empty_like(x)
for i in range(1, x.shape[0] - 1)
for j in range(1, x.shape[1] - 1)
out[i, j] = x[i + -1, j + -1] + x[i + -1, j + 0] + x[i + -1, j + 1] +
x[i + 0, j + -1] + x[i + 0, j + 0] + x[i + 0, j + 1] +
x[i + 1, j + -1] + x[i + 1, j + 0] + x[i + 1, j + 1]) // 9
return out
或者如果我们使用fancy的numba.stencil装饰器…
@numba.stencil
def _smooth(x)
return (x[-1, -1] + x[-1, 0] + x[-1, 1] +
x[ 0, -1] + x[ 0, 0] + x[ 0, 1] +
x[ 1, -1] + x[ 1, 0] + x[ 1, 1]) // 9
@numba.cuda.jit
def smooth_gpu(x, out)
i, j = cuda.grid(2)
n, m = x.shape
if 1 <= i < n - 1 and 1 <= j < m - 1
out[i, j] = (x[i - 1, j - 1] + x[i - 1, j] + x[i - 1, j + 1] +
x[i , j - 1] + x[i , j] + x[i , j + 1] +
x[i + 1, j - 1] + x[i + 1, j] + x[i + 1, j + 1]) // 9
Numba.cuda.jit已经发布多年了。它易于访问、成熟且有趣。如果您拥有一台带有GPU的机器并且有些好奇心,那么我们强烈建议您尝试一下。
conda install numba
# or
pip install numba
>>> import numba.cuda
正如之前的博客文章(1,2,3,4)所述,我们一直在推广Dask,使其不仅能处理Numpy数组和Pandas DataFrames,还能处理任何看起来足够像Numpy(如CuPy、Sparse或Jax)或足够像Pandas(如RAPIDS cuDF)的数据结构,从而扩展这些库的应用范围。这项工作进展顺利。这里有一个简短视频,展示了Dask Array并行计算SVD,并观察将Numpy库替换为CuPy时会发生什么。
我们看到计算性能提升了约10倍。最重要的是,只需微小的代码改动,我们就可以在CPU实现和GPU实现之间切换,同时继续使用Dask Array的复杂算法,比如其并行SVD实现。
我们也观察到通信速度相对变慢。总的来说,如今几乎所有非平凡的Dask + GPU工作都变得受限于通信。我们在计算方面已经足够快,以至于通信的相对重要性显著增加。我们正在努力通过下一个主题UCX来解决这个问题。
请参阅 Akshay Venkatesh 的这次演讲 或查看幻灯片
我们一直在通过UCX-Py将OpenUCX库集成到Python中。UCX提供了对TCP、InfiniBand、共享内存和NVLink等传输方式的统一访问。UCX-Py是许多这些传输方式首次可以轻松从Python语言访问的工具。
将UCX和Dask结合使用,我们可以获得显著的加速。这里是添加UCX前后SVD计算的跟踪记录
使用UCX之前:
使用UCX之后:
尽管如此,这里还有很多工作要做(上面链接的博客文章的“未来工作”部分有几项内容)。
人们可以使用高度实验性的conda包来尝试UCX和UCX-Py
conda create -n ucx -c conda-forge -c jakirkham/label/ucx cudatoolkit=9.2 ucx-proc=*=gpu ucx ucx-py python=3.7
我们希望这项工作也能影响在HPC系统上使用InfiniBand的非GPU用户,甚至由于易于访问共享内存通信而影响消费者硬件上的用户。
在之前的一篇博客文章中,我们讨论了安装与系统上安装的CUDA驱动程序不匹配的CUDA启用包的挑战。幸运的是,由于Anaconda的Stan Seibert和Michael Sarahan最近的工作,Conda 4.7现在有一个特殊的cuda元包,该元包设置为已安装驱动程序的版本。这将使未来的用户更容易安装正确的包。
Conda 4.7刚刚发布,除了cuda元包外,还附带了许多新功能。您可以在这里阅读更多信息。
conda update conda
如今在打包领域仍有大量工作要做。每个构建conda包的人都有自己的方式,这导致了头疼和异构性。这主要是因为缺乏像Conda Forge那样用于构建和测试CUDA启用包的集中式基础设施。幸运的是,Conda Forge社区正在与Anaconda和NVIDIA合作解决这个问题,尽管这可能需要一些时间。
本文更新了Python中GPU计算相关工作的进展。它还提供了各种链接供进一步阅读。如果您想了解更多信息,我们将其包含在下方
Copyright © 2022 Dask核心开发者。New-BSD许可证。




