这项工作得到了 Anaconda Inc. 和 NSF EarthCube 项目的支持。
我们最近宣布了美国国家大气研究中心 (NCAR)、哥伦比亚大学和 Anaconda Inc 之间的合作,旨在利用 XArray 和 Dask 加速高性能计算机 (HPC) 上大气和海洋数据的分析。提议工作的全文可在此处获取。我们非常感谢 NSF EarthCube 项目资助这项工作,鉴于近期大型风暴哈维、艾尔玛和何塞的影响(以及持续的威胁),这项工作在今天显得尤为重要。
这是哥伦比亚大学的学术科学家、NCAR 的基础设施管理员以及 Anaconda、哥伦比亚大学和 NCAR 的软件开发人员之间的一项合作,旨在将当前使用 XArray 和 Jupyter 的工作流程扩展到大型 HPC 系统和 PB 级数据集上。项目拨款结束后的第一周,我们中的几个人专注于寻找最快的途径,让科学团队在这些 HPC 系统上使用 XArray、Dask 和 Jupyter 快速启动并运行起来。这篇博文详细介绍了我们取得的成就以及在第一周发现的一些新挑战。我们希望将来能有更多关于此主题的博文。今天我们将介绍以下主题:
关于如何在 HPC 系统上将 Dask 部署到 XArray 的视频演示可在 YouTube 上观看,拥有 Cheyenne 超级计算机访问权限的大气科学家指南可在此处获取。
现在让我们开始讨论技术问题
HPC 系统使用 SGE、SLURM、PBS、LSF 等作业调度器。Dask 之前已被学术团体或金融公司部署在所有这些系统上。然而,每次这样做时,情况都会略有不同,并且通常是为特定的集群量身定制的。
我们想做一些更通用的东西。这最初是一个关于 PBS 脚本的 GitHub issue,旨在创建一个简单的通用模板供人们复制和修改。不幸的是,这遇到了重大挑战。HPC 系统及其作业调度器似乎只专注于并轻松支持两种常见的使用案例:
部署 Dask 介于这两者之间。它属于主从模式(或者更确切地说是协调器-工作器模式)。我们最终构建了一个启动 Dask 的 MPI4Py 程序。所有 HPC 作业调度器都很好地支持 MPI,更重要的是它们对 MPI 的支持是一致的,因此依赖 MPI 可以提供跨机器的稳定性。现在 dask.distributed 附带一个新的 dask-mpi 可执行文件
mpirun --np 4 dask-mpi
需要澄清的是,Dask 并非使用 MPI 进行进程间通信。它仍然使用 TCP。我们只是使用 MPI 来启动一个调度器和几个工作器并将它们连接在一起。伪代码中,dask-mpi 可执行文件看起来像这样
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
if rank == 0
start_dask_scheduler()
else
start_dask_worker()
从社交角度看,这很有用,因为每个集群管理团队都知道如何支持 MPI,因此任何拥有此类集群访问权限的人都可以找到可以寻求帮助的对象。我们已成功地将“如何启动 Dask?”的问题转化为“如何运行此 MPI 程序?”的问题,超级计算机设施的技术人员通常更容易处理这个问题。
我们的合作重点是大型数据集的交互式分析。这意味着人们期望打开 Jupyter notebook,连接到由多台机器组成的集群,并在他们坐在电脑前时在这些机器上进行计算。
不幸的是,大多数作业调度器都是为批处理调度设计的。它们会尝试快速运行您的作业,但也不介意等待几个小时,以便超级计算机上有一组合适的机器空闲出来。随着您请求更多时间和更多机器,等待时间可能会急剧增加。对于大多数 MPI 作业来说,这没什么问题,因为人们不期望立即得到结果,而且他们肯定不会与程序进行交互,但在我们的案例中,我们确实希望立即得到一些结果,即使它们只是我们请求的一部分。
长期解决这个问题需要技术工作和政策决策。短期内,我们利用了两个事实:
因此我发现,如果我请求几个单机作业,我可以轻松地拼凑出一个快速启动的相当大的集群。实际上,这看起来像这样
qsub start-dask.sh # 只请求一台机器
qsub add-one-worker.sh # 再请求一台机器
qsub add-one-worker.sh # 再请求一台机器
qsub add-one-worker.sh # 再请求一台机器
qsub add-one-worker.sh # 再请求一台机器
qsub add-one-worker.sh # 再请求一台机器
qsub add-one-worker.sh # 再请求一台机器
我们的主要作业的运行时长约为一小时。工作器的运行时长较短。它们可以在计算过程中根据我们的计算需求变化随时加入或离开。
我们的科学合作者喜欢为他们的工作构建 Jupyter notebook。这使他们能够一次性管理他们的代码、科学思考和可视化输出,并对他们来说是一个可以与他们的科学团队和合作者共享的成果。为了帮助他们,我们在他们分配的正在运行 Dask 调度器的同一台机器上启动一个 Jupyter 服务器。然后,我们向他们提供 SSH 隧道命令行,他们可以复制粘贴这些命令,以便从个人电脑访问 Jupyter 服务器。
我们一直在使用新的 Jupyter Lab 而非经典的 notebook。这对我们来说特别方便,因为它提供了他们在不使用本地机器工作时所失去的大部分交互式体验。他们无需反复 SSH 进入 HPC 系统,就可以获得文件浏览器、终端、文本文件轻松可视化等功能。我们通过一个连接和直观的 Jupyter 界面即可获得所有这些功能。
目前,我们为他们提供了一个脚本来设置所有这些。该脚本使用 Dask 启动 Jupyter Lab,然后打印出 SSH 隧道命令行。
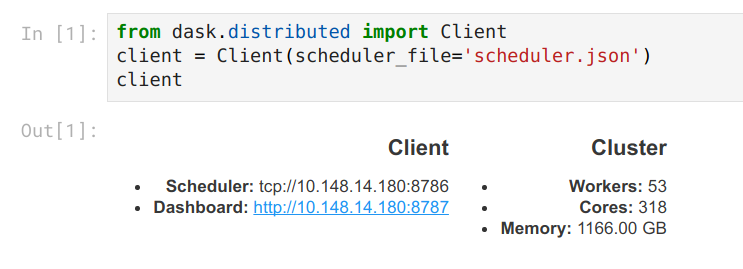
from dask.distributed import Client
client = Client(scheduler_file='scheduler.json')
import socket
host = client.run_on_scheduler(socket.gethostname)
def start_jlab(dask_scheduler)
import subprocess
proc = subprocess.Popen(['jupyter', 'lab', '--ip', host, '--no-browser'])
dask_scheduler.jlab_proc = proc
client.run_on_scheduler(start_jlab)
print("ssh -N -L 8787:%s:8787 -L 8888:%s:8888 -L 8789:%s:8789 cheyenne.ucar.edu" % (host, host, host))
从长远来看,我们希望切换到完全的点击式界面(也许像 JupyterHub 那样),但这需要额外考虑如何在部署 Jupyter 服务器实例的同时部署分布式资源。
预期的计算将在集群中移动数 TB 的数据。在这个集群上,Dask 使用高速 InfiniBand 网络,每台机器可获得约 1GB/s 的同步读写网络带宽。对于任何商品化或基于云的系统来说,这都非常快(比我在亚马逊上观察到的速度快约 10 倍)。然而,对于超级计算机来说,这仅占其潜在能力的约 30%(参见硬件规格)。
我怀疑这与 Dask 在底层使用的网络库 Tornado 的字节处理方式有关。下图显示了通信密集型工作负载后一个工作器的诊断仪表盘。我们看到读写速度均为 1GB/s。我们还看到 100% 的 CPU 使用率。

对于关注 Dask 的 HPC 用户来说,网络性能是一个大问题。如果我们能接近 MPI 带宽,那么这可能有助于减少这个注重性能的社区的担忧。
XArray 是第一个在内部使用 Dask 的主要项目。这种早期集成对于通过用户反馈来验证 Dask 的内部结构至关重要。然而,这也意味着 XArray 的一些部分是在 Dask 的一些较新部分(特别是异步分布式调度功能)出现之前设计的。
XArray 仍然可以在分布式集群上使用 Dask,但只能使用与单机调度器相同的特性子集。这意味着,与应该的情况相比,今天使用 XArray 在分布式 RAM 中持久化数据、并行调试、发布共享数据集等方面都需要更多的工作量。
为了解决这个问题,我们计划更新 XArray,使其遵循一个新的Dask 接口提议。该接口足够复杂,可以处理所有 Dask 调度功能,但又足够轻量级,实际上不需要依赖 Dask 库本身。(吉姆·克里斯特 (Jim Crist) 的工作。)
我们最终还需要考虑减少检查多个 NetCDF 文件时的开销,但我们尚未遇到这个问题,因此我打算先等等看。
我们认为目前的进展对于科学用户开始试用该系统来说已经相当不错了。我们有一个“在 Cheyenne 上使用 Dask 入门”的 Wiki 页面,第一批试用用户已经成功地按照指引操作,没有遇到太多麻烦。我们还确定了一些问题,软件开发人员可以在科学团队启动的同时着手解决。
我们非常希望在此过程中与其他合作者进行交流。如果您或您的团队正在研究相关问题,我们非常希望听到您的声音。这项拨款不仅仅是为了满足哥伦比亚大学和 NCAR 研究人员的科学需求,更是为了构建能够造福整个大气和海洋科学社区的长期系统。请在Pangeo GitHub issue 跟踪器上参与讨论。
版权所有 © 2022 Dask 核心开发者。根据 New-BSD 许可授权。




